Визуальное и интерактивное руководство по основам нейронных сетей 🧠
- ·
-

Я не эксперт в области машинного обучения. Я по образованию инженер-программист и мало сталкивался с ИИ. Я всегда хотел глубже погрузиться в машинное обучение, но никак не мог найти подходящий момент. Поэтому, когда Google выложил TensorFlow в открытый доступ в ноябре 2015 года, я был в восторге и понял, что пришло время начать путь изучения. Не хочу звучать драматично, но для меня это действительно ощущалось как будто Прометей передаёт огонь человечеству с Олимпа машинного обучения. На заднем плане у меня крутилась мысль о том, как вся область Больших Данных и технологии вроде Hadoop резко ускорились после публикации статьи Google про MapReduce. Но теперь это не просто статья — это само программное обеспечение, которое они использовали у себя внутри после многих лет развития.
Так что я начал изучать основы темы и увидел, что людям без опыта в этой области нужны более простые и понятные ресурсы. Это моя попытка создать такой ресурс.
Начнём отсюда
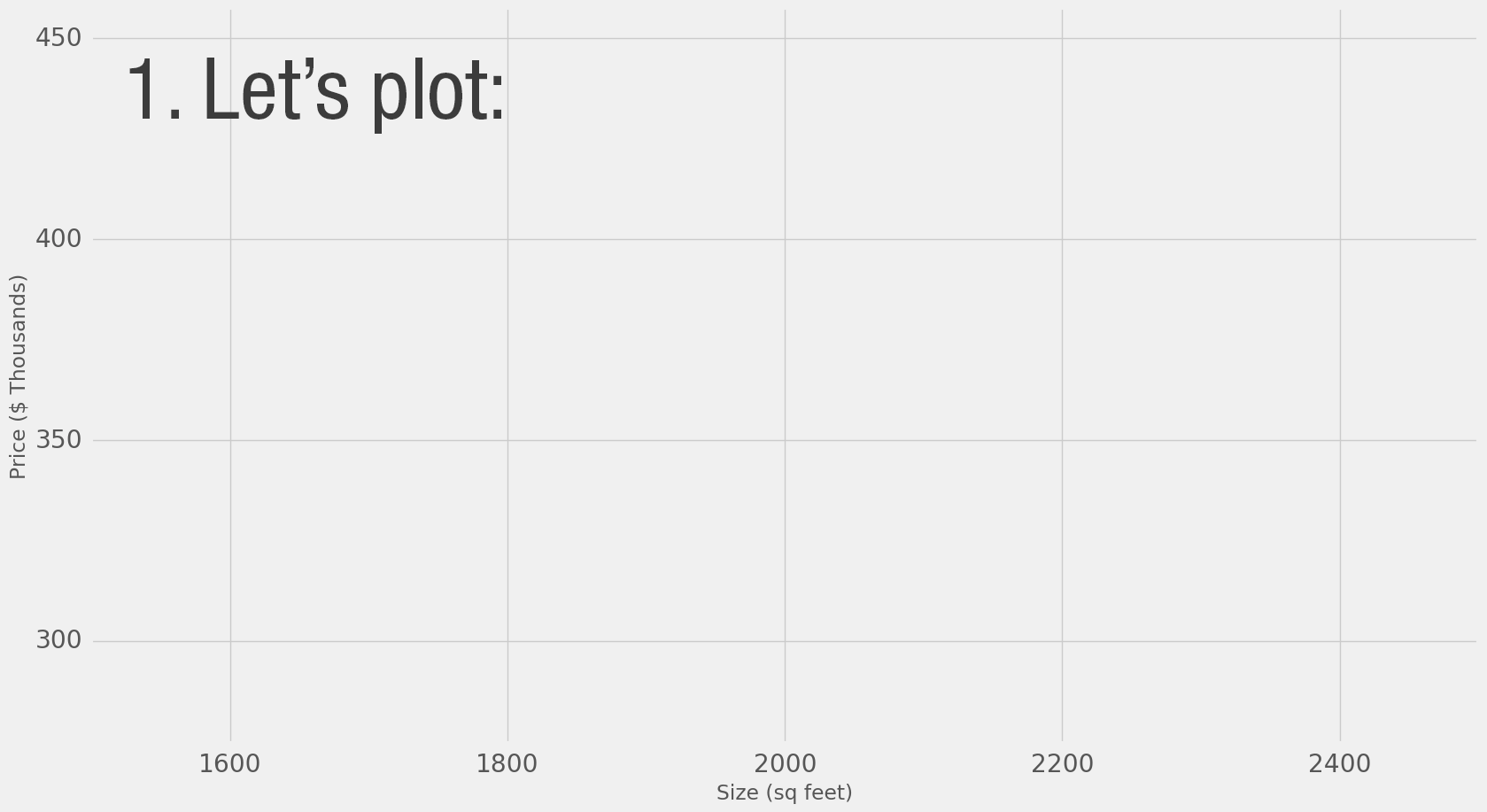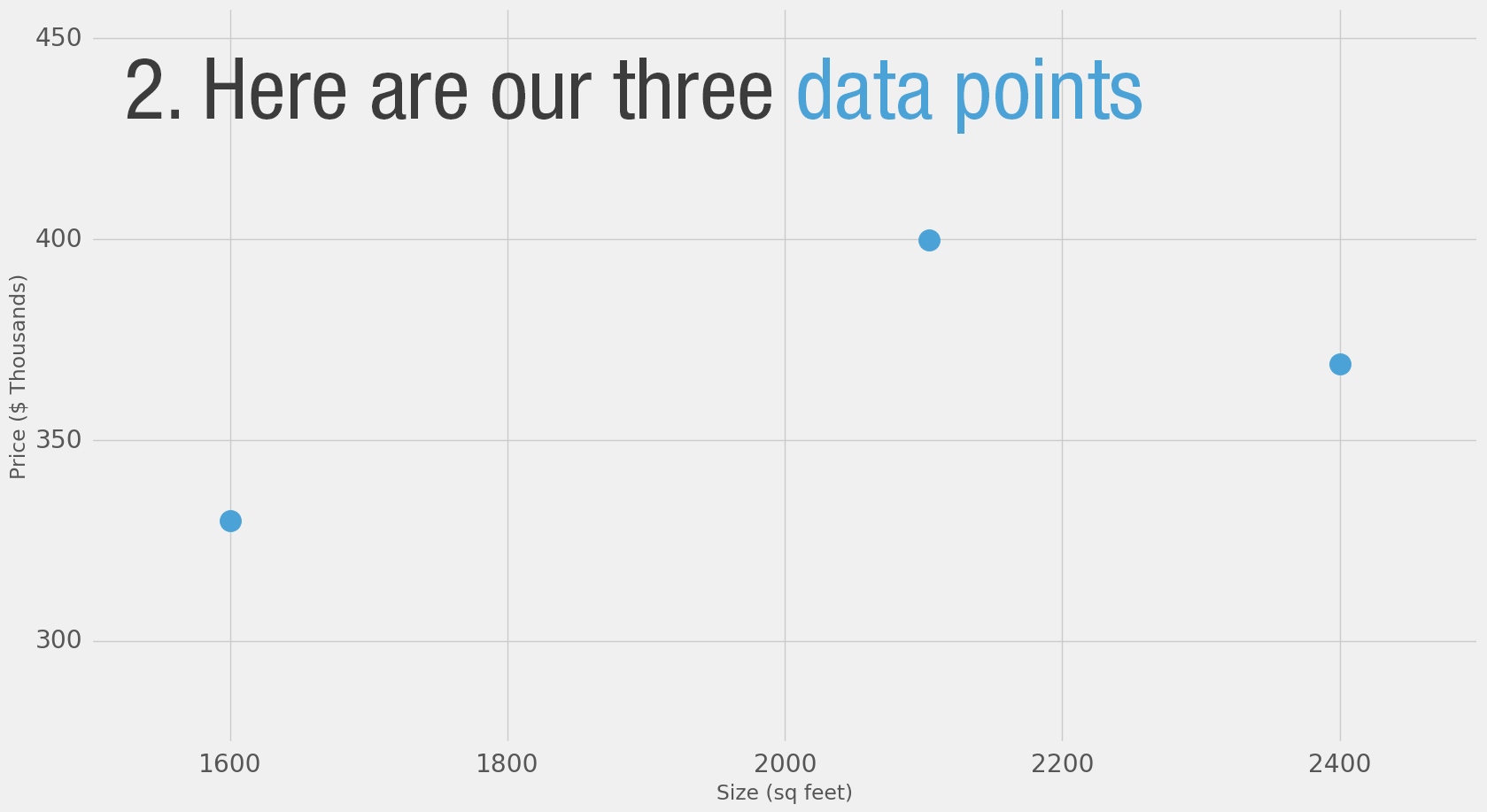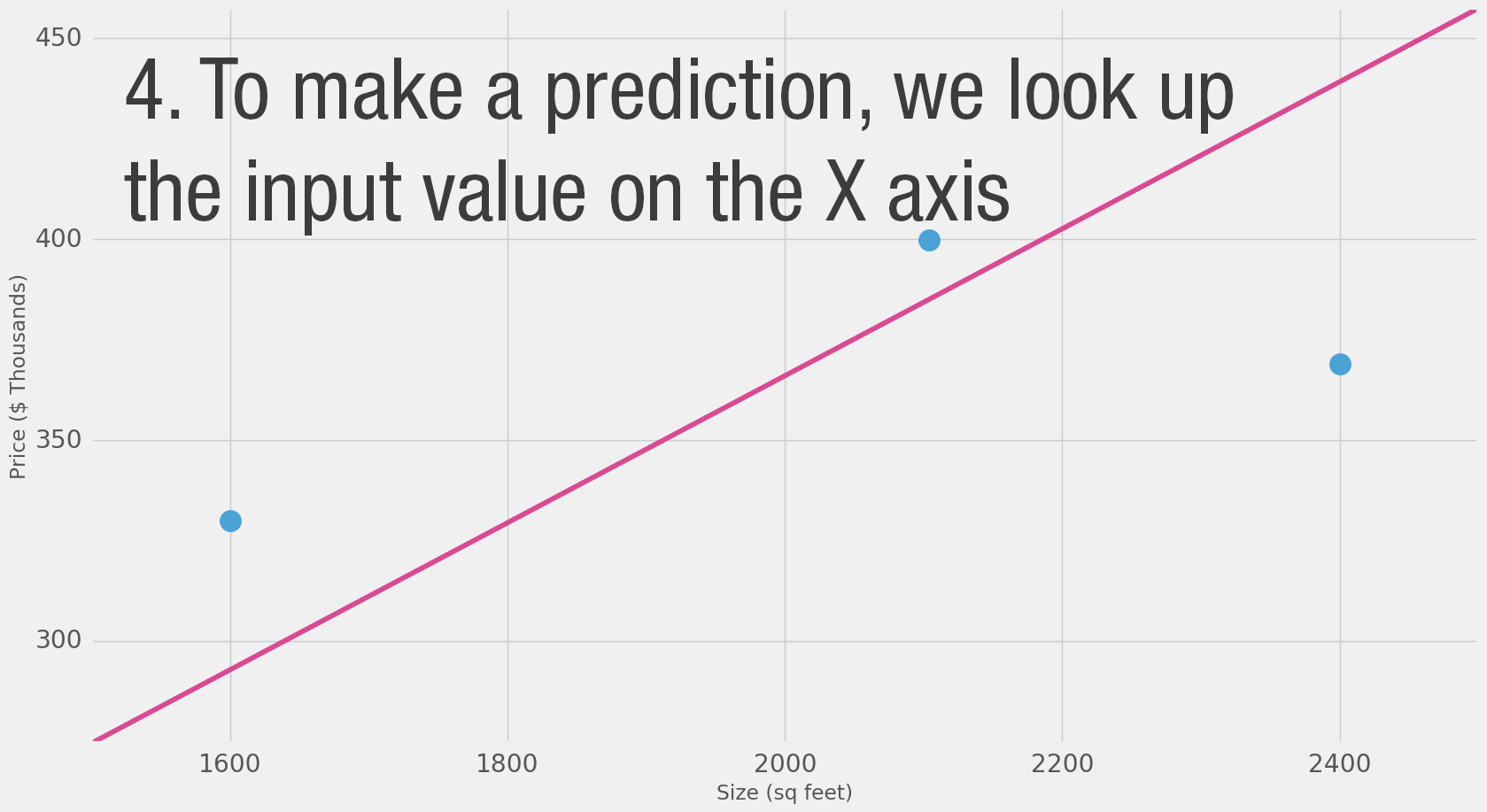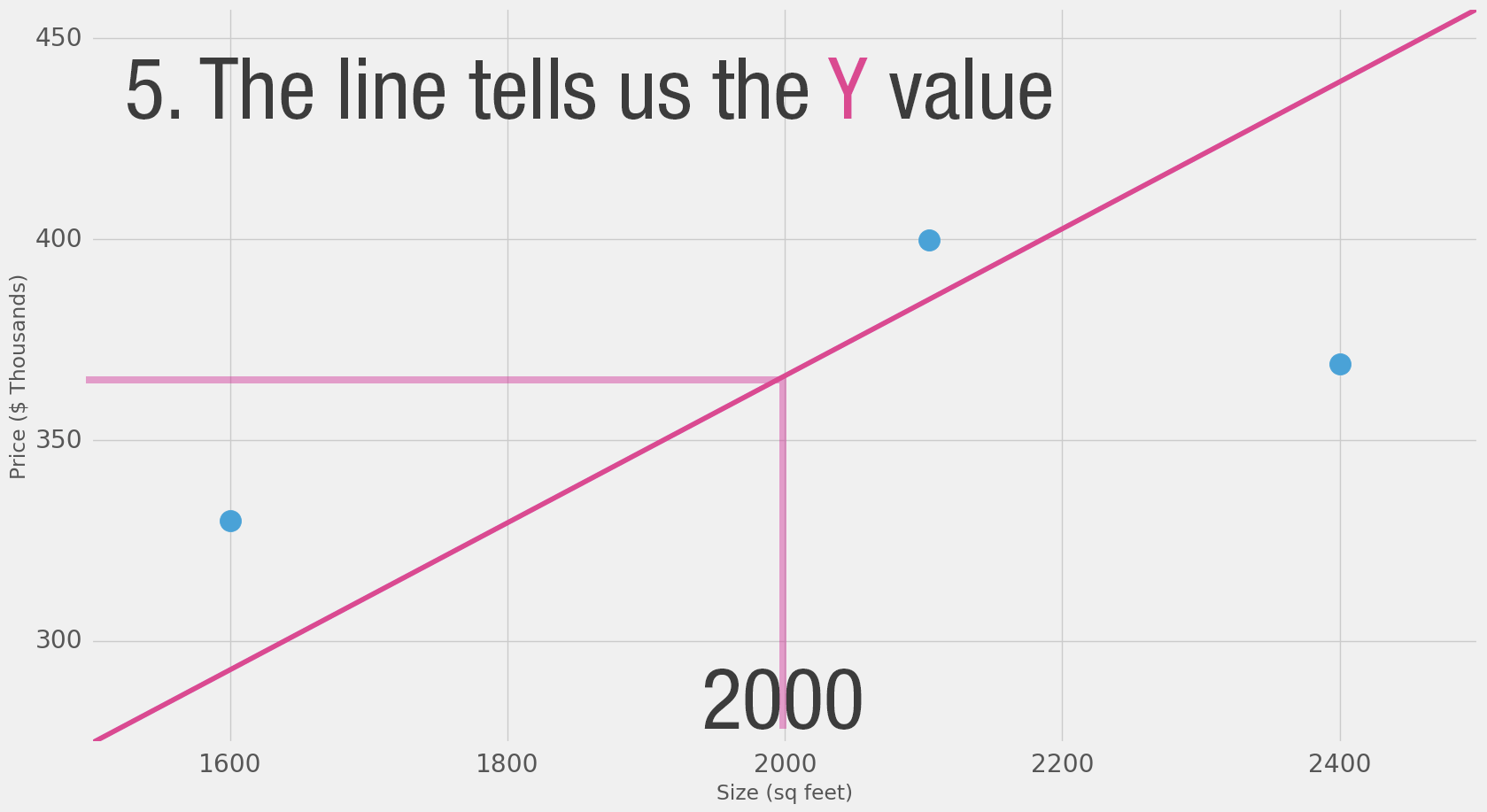
Давайте начнём с простого примера. Допустим, вы помогаете подруге, которая хочет купить дом. Ей предложили дом площадью 2000 квадратных футов (185 квадратных метров) за $400,000. Хорошая ли это цена?
Трудно сказать без точки отсчёта. Поэтому вы спрашиваете своих друзей, которые покупали дома в этом же районе, и в итоге получаете три примера:
| Площадь (кв. футы) (x) | Цена (y) |
|---|---|
| 2,104 | 399,900 |
| 1,600 | 329,900 |
| 2,400 | 369,000 |
Лично у меня первая мысль — посчитать среднюю цену за квадратный фут. Она составляет $180 за кв. фут.
Добро пожаловать в вашу первую нейронную сеть! Пока она, конечно, ещё не на уровне Siri, но вы уже знаете её фундаментальный строительный блок. И выглядит он так:
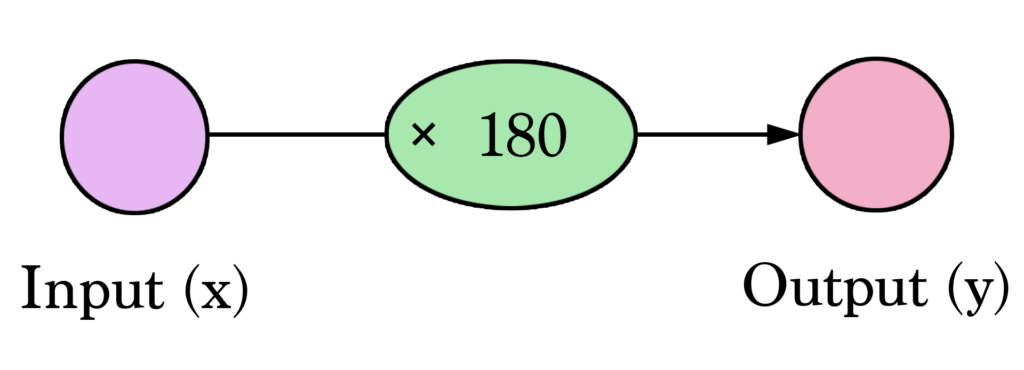
Такие диаграммы показывают структуру нейронной сети и то, как она делает предсказания. Вычисление начинается с входного узла слева. Значение на входе движется вправо, умножается на вес, и результат становится нашим выходом.
Умножив 2,000 кв. футов на 180, мы получаем $360,000. На этом уровне всё именно так просто. Предсказание — это обычное умножение. Но перед этим нужно было подумать, какой вес мы будем использовать для умножения. В данном случае мы начали со среднего значения, но позже рассмотрим более продвинутые алгоритмы, которые могут масштабироваться по мере увеличения количества входов и усложнения моделей. Поиск веса — это и есть этап «обучения». Так что когда вы слышите, что кто-то «обучает» нейронную сеть — это просто означает, что он подбирает веса, с помощью которых делаются предсказания.
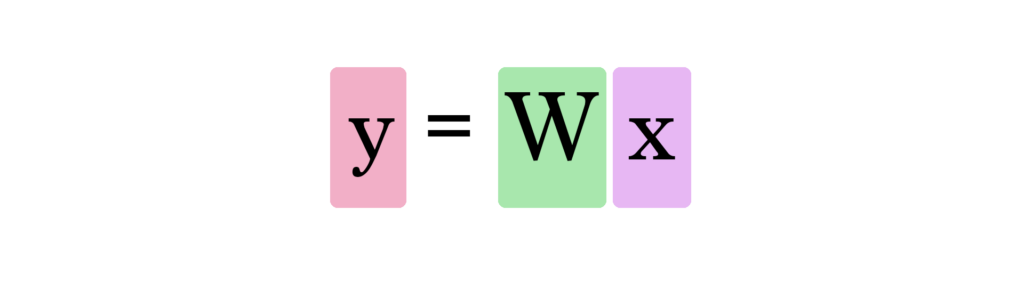
Это форма предсказания. Это простая предсказательная модель, которая принимает входные данные, выполняет вычисление и выдаёт результат (поскольку результат может быть непрерывным значением, техническое название такой модели — «регрессионная модель»).
Давайте визуализируем этот процесс (для простоты переключим единицу измерения цены с долларов на тысячи долларов. Теперь наш вес — 0.180 вместо 180):
Труднее, лучше, быстрее, сильнее
Можем ли мы предсказать цену лучше, чем просто используя среднее значение по нашим данным? Давайте попробуем. Сначала определим, что значит «лучше» в этом случае. Если мы применим нашу модель к тем трём точкам данных, которые у нас есть, насколько хорошо она сработает?
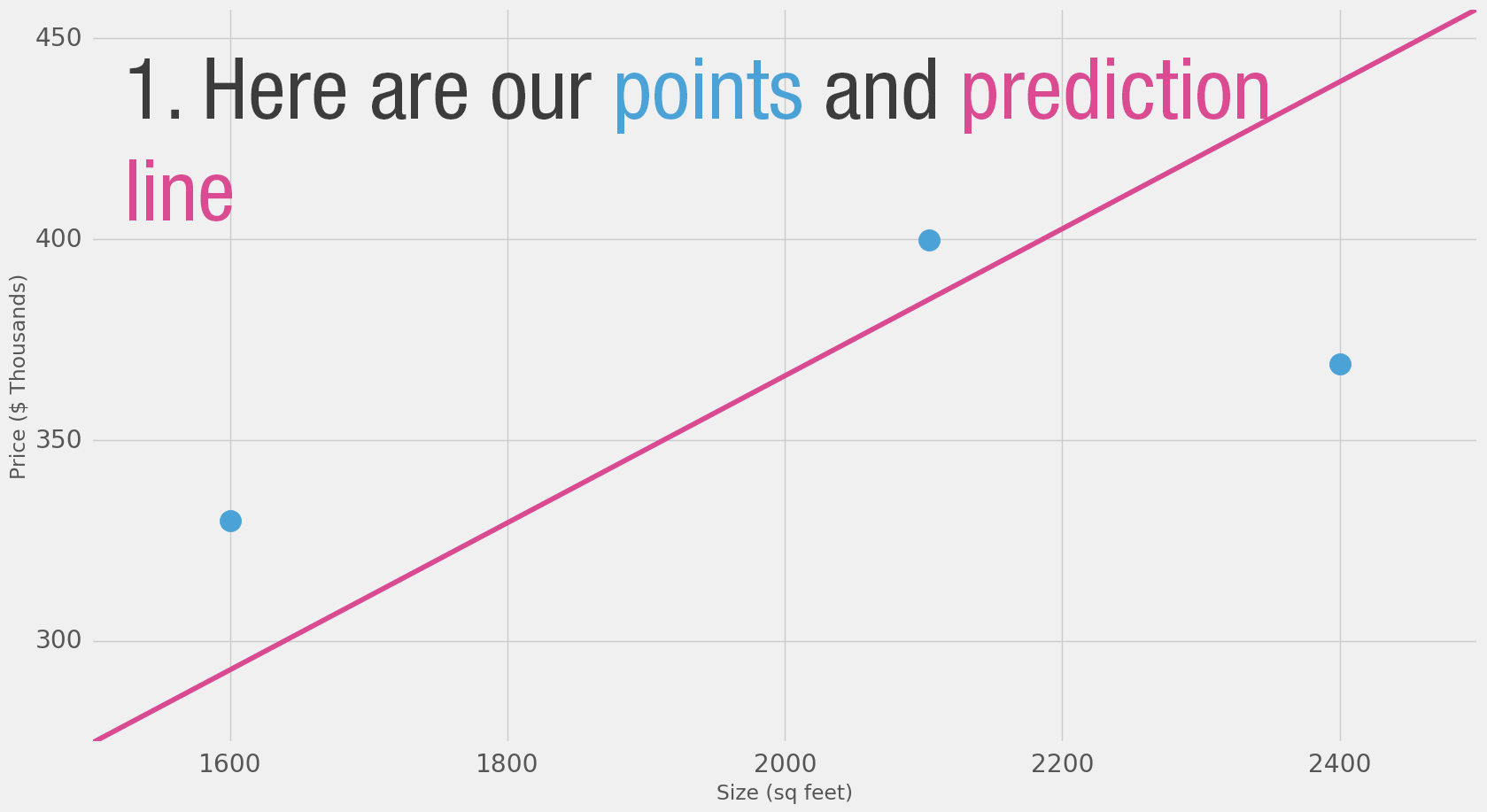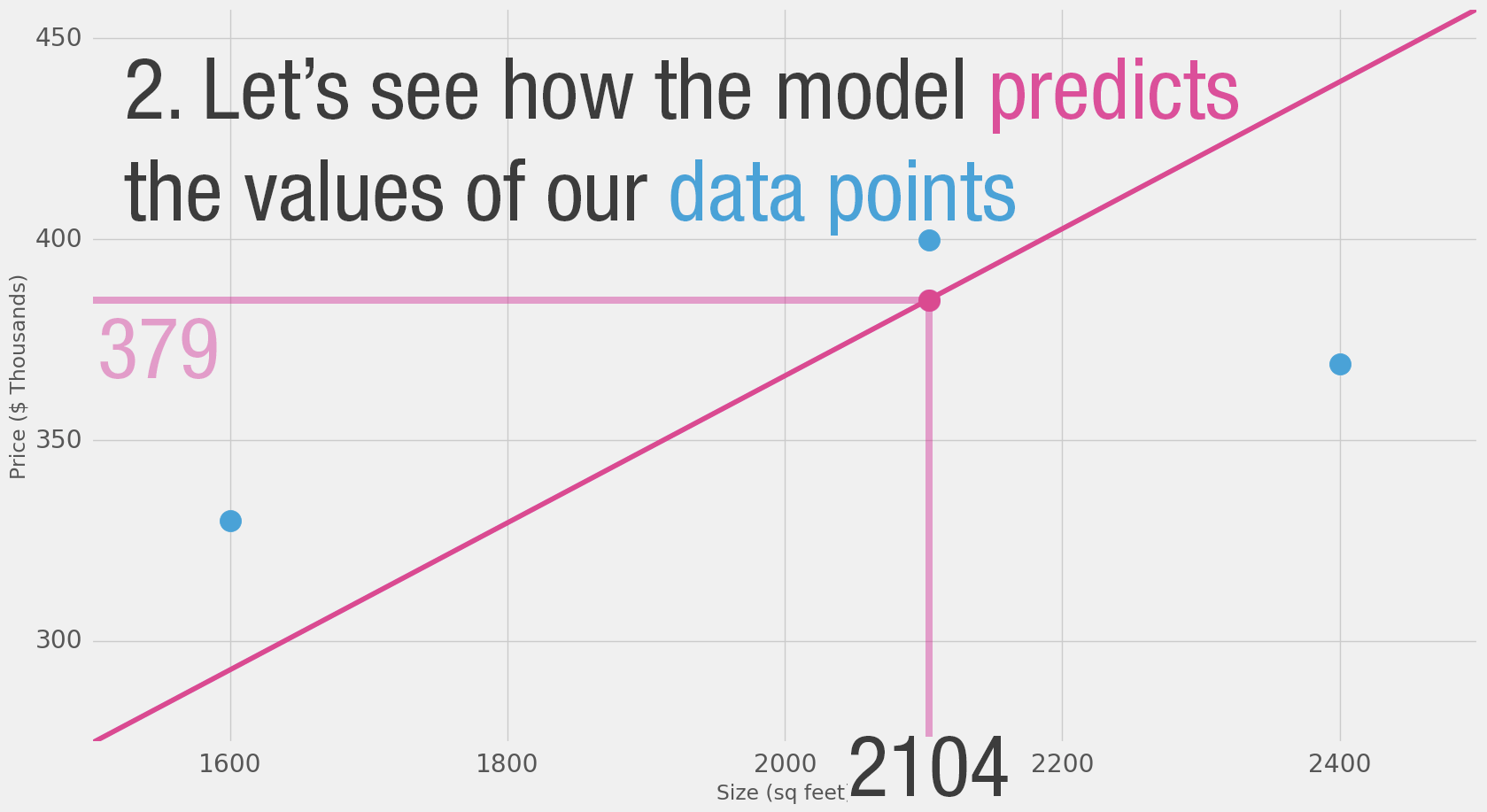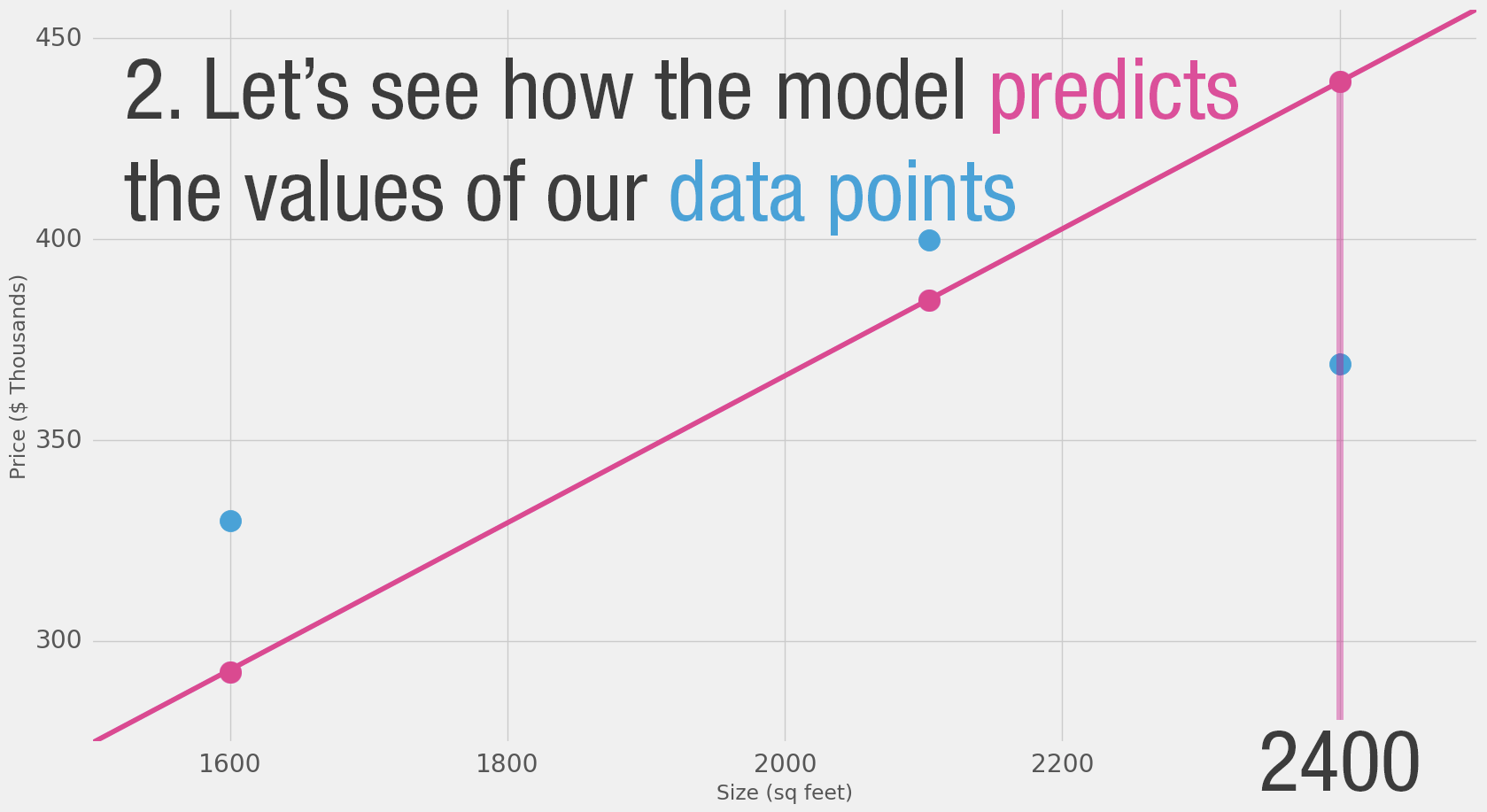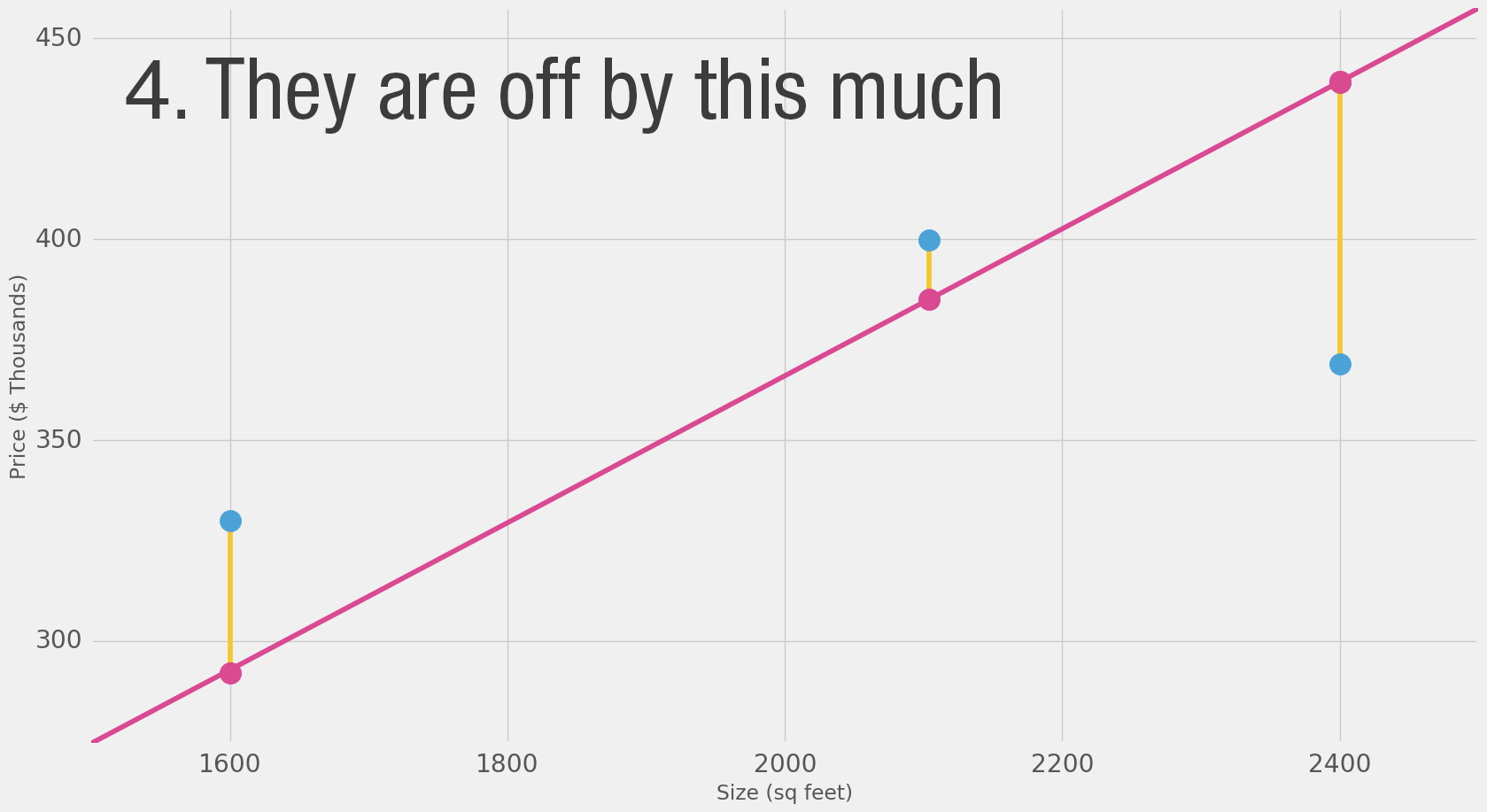
Это довольно много жёлтого. Жёлтый — это плохо. Жёлтый — это ошибка. Мы хотим уменьшить жёлтый как можно больше.
| Площадь (x) | Цена ($1000) (y_) | Предсказание (y) | y_—y | (y_—y)² |
|---|---|---|---|---|
| 2,104 | 399.9 | 379 | 21 | 449 |
| 1,600 | 329.9 | 288 | 42 | 1756 |
| 2,400 | 369 | 432 | —63 | 3969 |
| Среднее: | 2,058 | |||
Здесь мы видим фактическое значение цены, предсказанное значение цены и разницу между ними. Затем нам нужно вычислить среднее этих разниц, чтобы получить число, которое покажет, насколько велика ошибка в этой модели предсказания. Проблема в том, что в 3-й строке разница равна -63. Мы должны обработать это отрицательное значение, если хотим использовать разницу между предсказанием и ценой как меру ошибки. Поэтому мы вводим дополнительный столбец, который показывает ошибку в квадрате, таким образом избавляясь от отрицательного значения.
Теперь это наша дефиниция улучшения модели — лучшая модель — это та, у которой меньше ошибок. Ошибка измеряется как среднее значение ошибок для каждой точки в нашем наборе данных. Для каждой точки ошибка измеряется как разница между фактическим значением и предсказанным значением, возведённая в квадрат. Это называется Среднеквадратичной Ошибкой (Mean Squared Error). Использование её в качестве ориентира для обучения модели делает её нашей функцией потерь (также называемой функцией стоимости).
Теперь, когда мы определили меру для лучшей модели, давайте попробуем несколько других значений веса и сравним их с нашим средним вариантом:
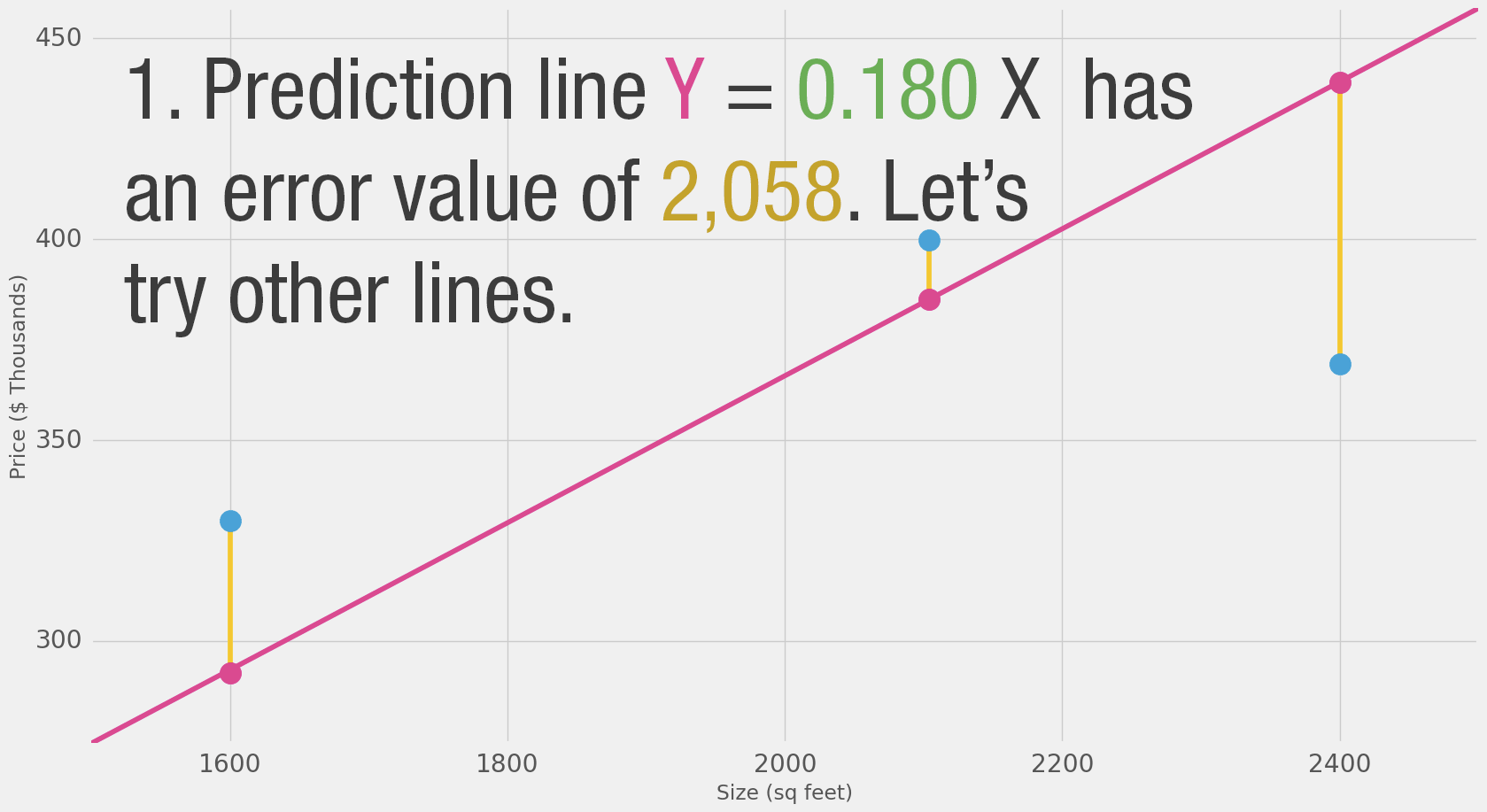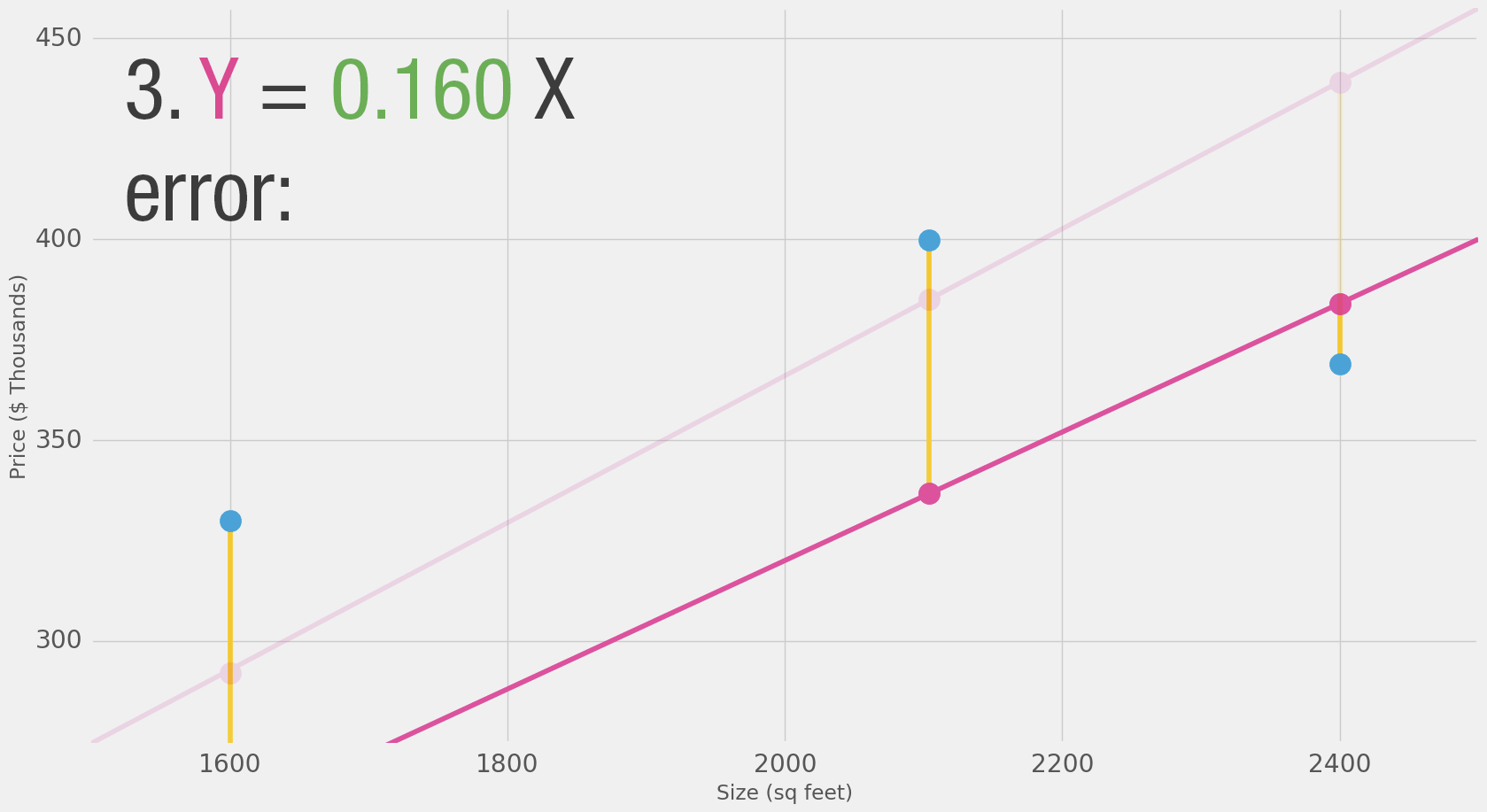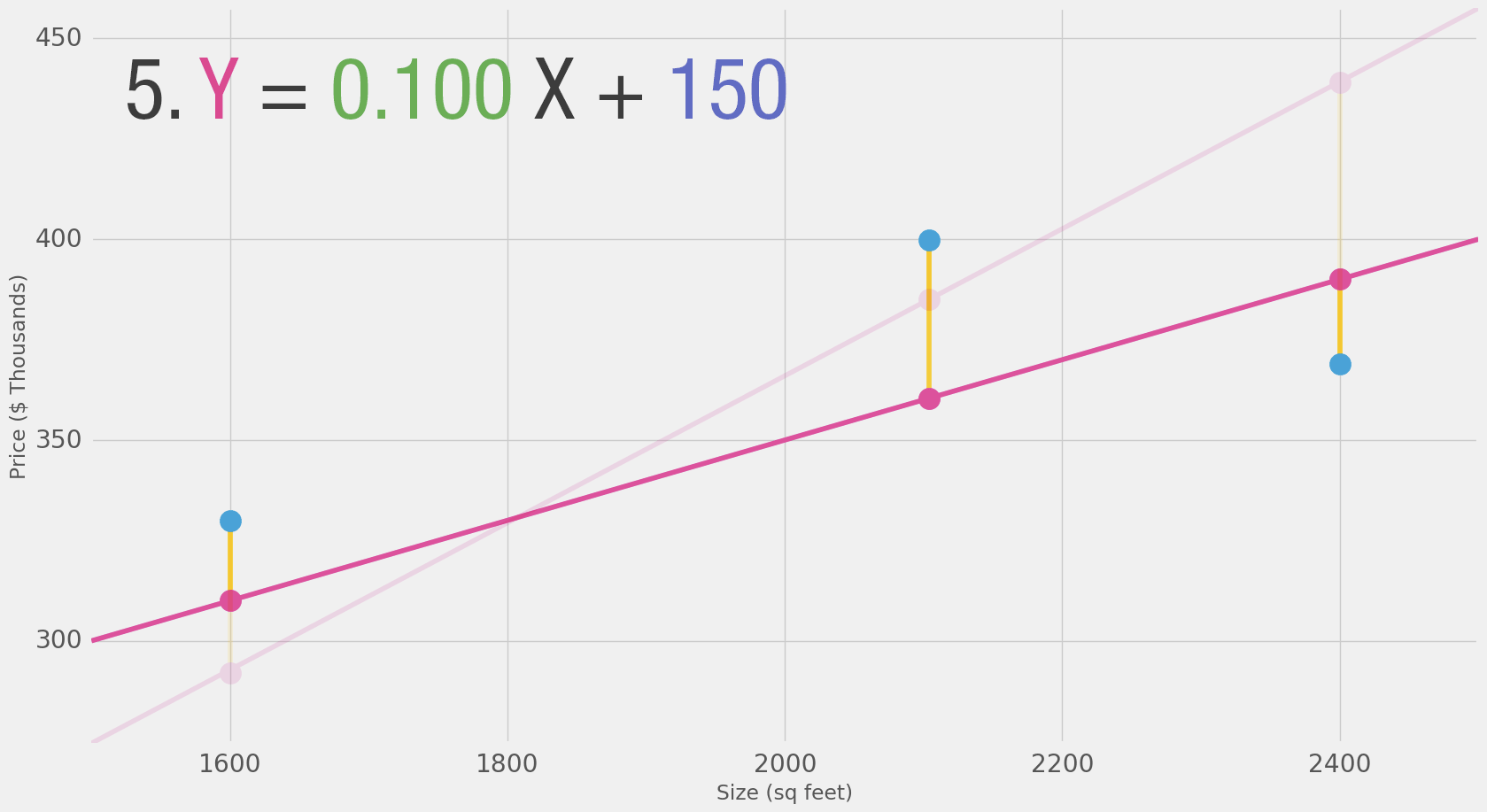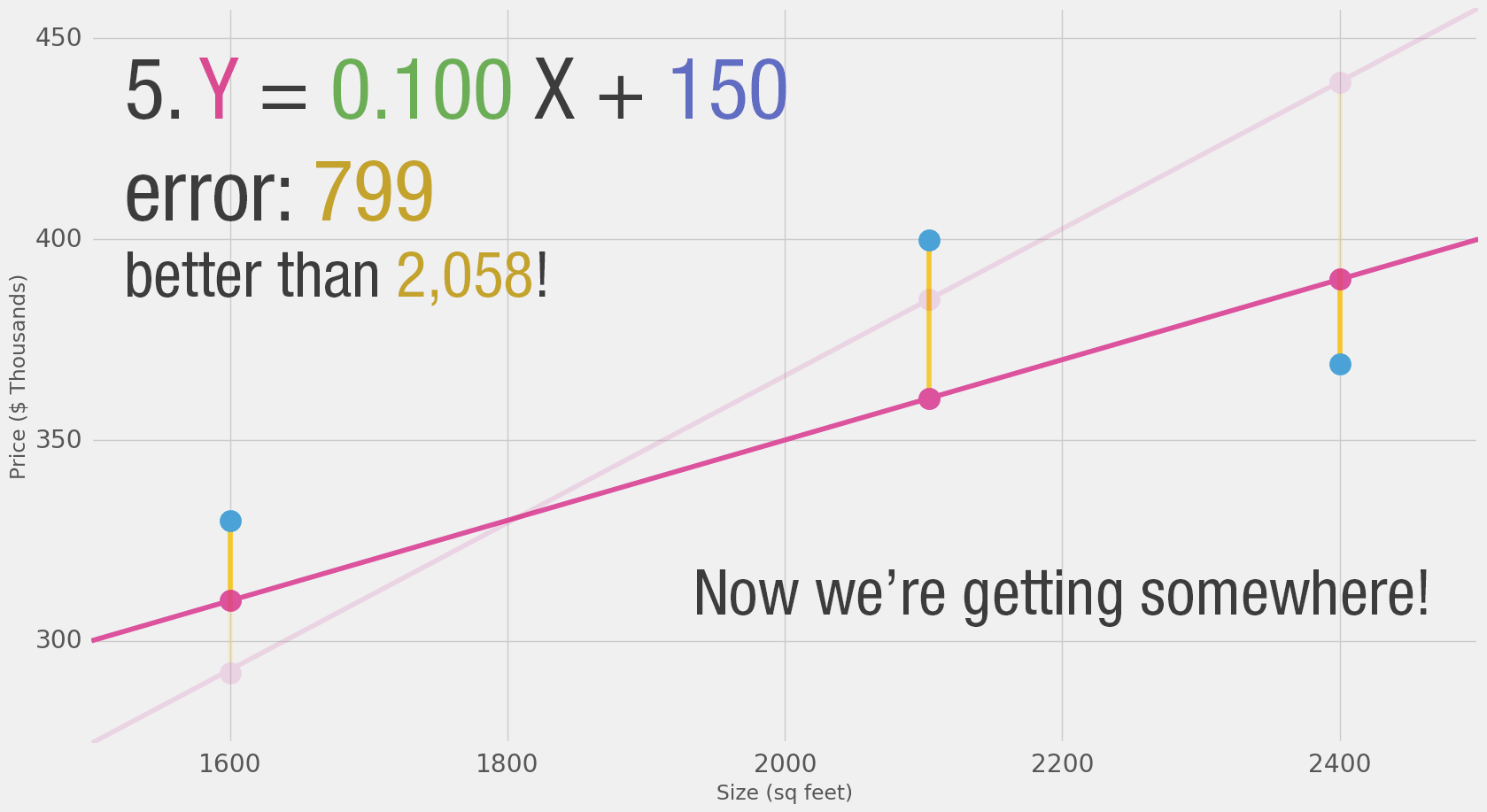
Теперь, когда мы добавили значение смещения (b) в формулу линии, наши линии могут лучше приближать значения. В этом контексте мы называем его «смещением». Это делает нашу нейронную сеть такой:
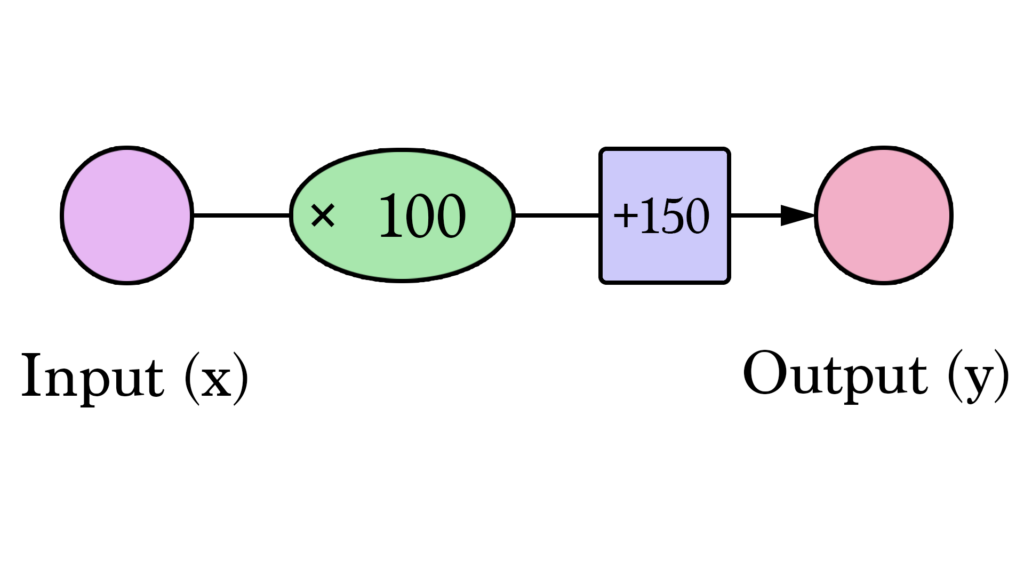
Мы можем обобщить это, сказав, что нейронная сеть с одним входом и одним выходом (спойлер: и без скрытых слоёв) выглядит так:
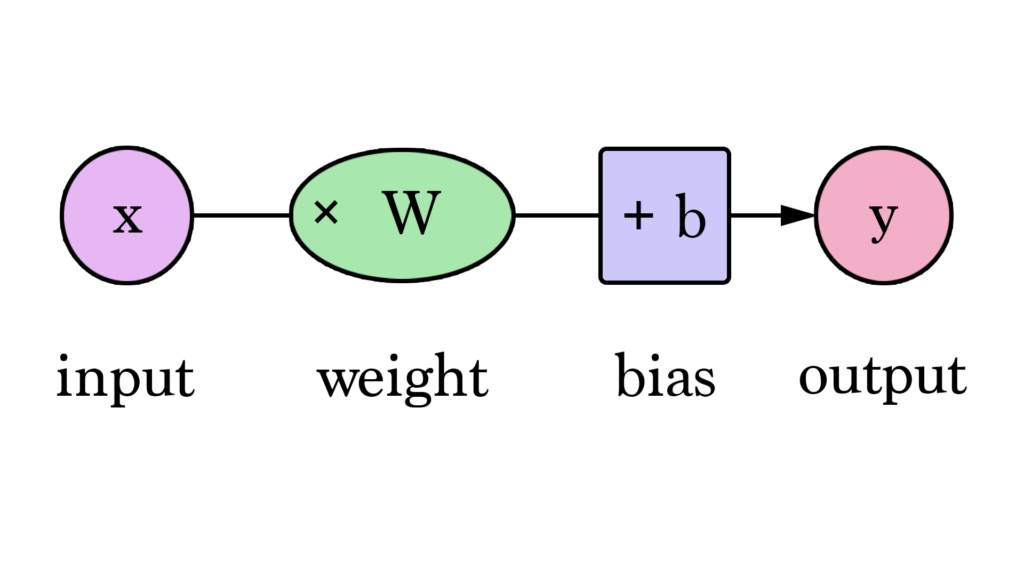
На этом графике W и b — это значения, которые мы находим в процессе обучения. X — это входное значение, которое мы подставляем в формулу (площадь в квадратных футах в нашем примере). Y — это предсказанная цена.
Теперь для вычисления предсказания используется следующая формула:
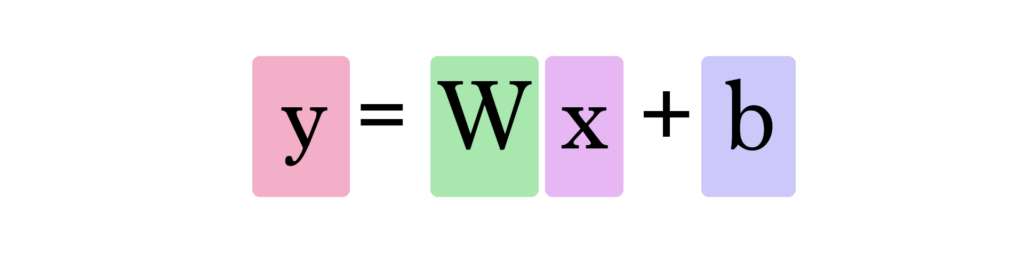
Таким образом, наша текущая модель вычисляет предсказания, подставляя площадь дома в качестве x в эту формулу:
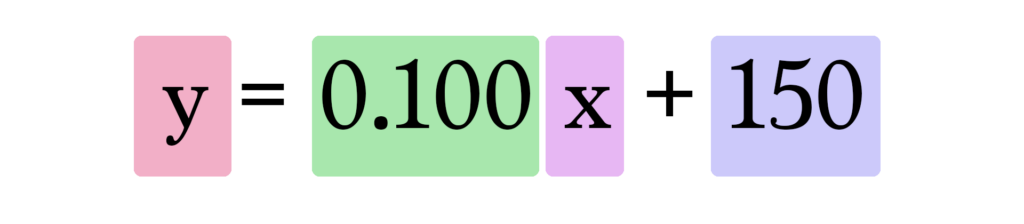
В заключении вы можете интерактивно попробовать научить Вашу первую игрушечную модель на сайте автора статьи.
A Visual and Interactive Guide to the Basics of Neural Networks